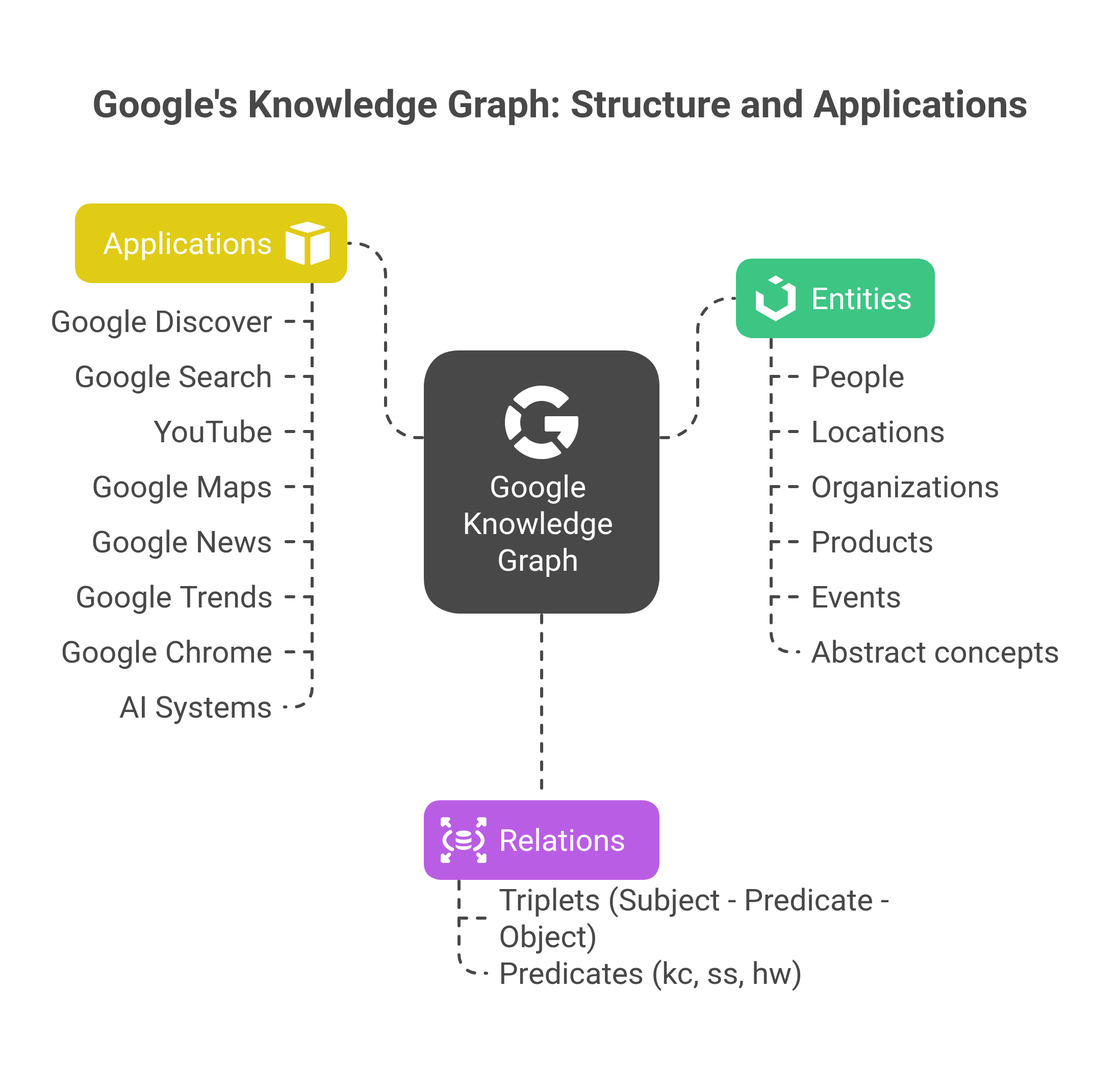
Entities Everywhere: The Knowledge Graph, the Invisible Architecture of the Google Empire
The Knowledge Graph is no longer merely a database that enriches search results - it has become the foundational infrastructure on which the Mountain View giant’s entire AI and Search strategy now rests.
A sprawling system with unsuspected ramifications
Our investigation reveals an architecture of dizzying complexity. What we once assumed was a simple knowledge base powering the Knowledge Panels is, in fact, an interconnected ecosystem that literally courses through every Google service: Search, Discover, YouTube, Maps, Assistant, and now the new AI systems such as Gemini and AI Overviews.
The obsession with validation: trusted authors and sources
Google is deadly serious about the reliability of its data. The Livegraph system, the beating heart of the Knowledge Graph, assigns a confidence weight to every identified triple in order to decide whether or not to include it in the KG. The decision varies according to the trust Google places in the site or the author. For example, if the author already has a Google‑validated profile with a Knowledge Panel, their score is automatically boosted. This verification obsession shows up in the complex hierarchy of namespaces:
- kc: data from highly validated corpora (official age, government data)
- ss: webfacts extracted from the web (less reliable but richer) ‑ you will also find a few ok: shortfacts
- hw: data manually curated by humans
This classification is anything but trivial - it directly determines the level of trust granted to each piece of information and how that information is used across Google’s various services.
Ghost entities: when Google fills the gaps
A fascinating discovery concerns the “unanchored entities.” Unlike official entities that possess a stable identifier (Freebase MID, and so on), these ghost entities float in a buffer zone, used temporarily by Google’s systems without being formally integrated into the Knowledge Graph.
This flexibility enables Google to react in near‑real time to emerging events - a major strategic advantage over, for example, traditional LLMs that rely on static training data.
The extraction pipeline: a semantic war machine
SAFT, WebRef and the race for entities
Google’s extraction systems run 24 / 7 to identify, classify and link entities. SAFT (Structured Annotation Framework and Toolkit) does far more than pull out names: it analyses relations, context and coreference, building a complete semantic representation of every document. Several mechanisms are at work. A few examples:
- SAFT identifies entities and their relationships
- WebRef / QRef resolves ambiguities (Apple Inc. vs apple)
- Tractzor and Chain Mining extract long‑tail entities
- The “singleTopicness” score assesses relevance
- …
Predicates: the DNA of relationships
Our analyses reveal hundreds of predicates structuring the links between entities. From the simple kc:/people/person:age to complex relations such as hw:/collection/olympic_athletes:gold medal, each predicate encodes a specific facet of human knowledge.
Even more intriguing, the appearance of French‑language predicates (ss:/webfacts:lieu_de_creation_en_franc, ss:/webfacts:mair_mandat) suggests a local adaptation of the Knowledge Graph, potentially to improve the regional relevance of results.
The impact on Discover and beyond
When entities drive the news
Recent Google experiments (EntityCardDynamicChipsAndSubtitlesLaunch, DeepscamImplicitEntityLaunch) show a determination to weave entities ever more deeply into the user experience. On Discover in particular, every card is now tied to a set of entities that governs its distribution and visibility.
Damien Andell’s analysis reveals astonishing real‑time update mechanisms: during shows like Danse with Stars, the entities for the contestants see their trend score skyrocket minute by minute, instantly influencing their visibility on Discover.
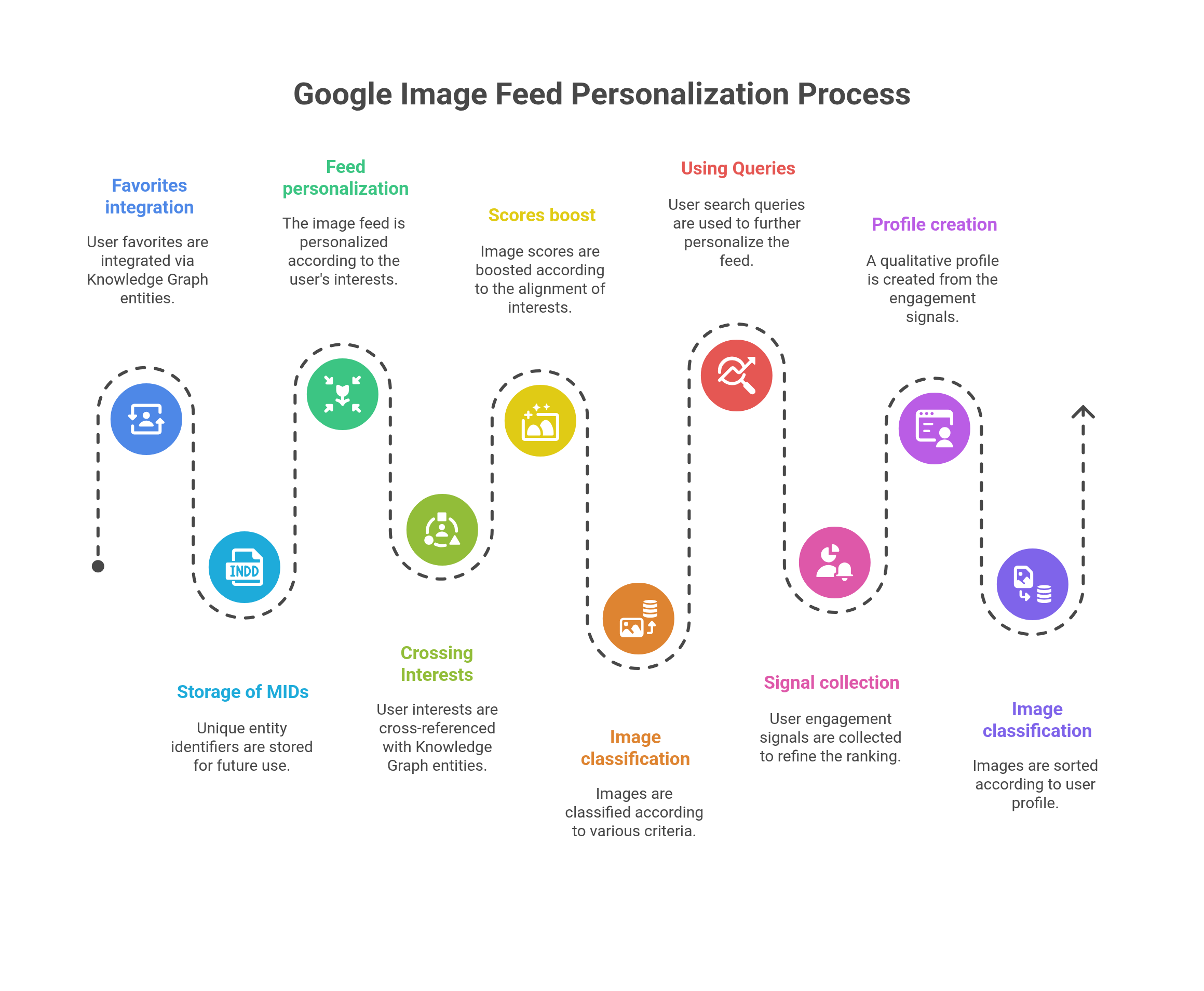
Image Feed: when your favorites drive your recommendations
Another discovery by Damien reveals how the image feed (Ember) works in the Google app, which coexists with Google Discover. In the “Activity” tab, Google stores collections of saved items such as the Watchlist (movies/series) and FavoritePlaces (maps), retaining the corresponding entity MIDs through the ActivityHub.
Examples of entity storage:
- "item_type: PLACE", "/m/0c9888"
- "item_type: TVM_ENTITY", "/g/11k9fvbhqw"
The system becomes particularly sophisticated inside the image feed. Google cross‑references ad topics (for example #910 Soups & Stews) with entity MIDs, and the score is boosted by VERTICAL_AFFINITY_EXPLICIT_INTEREST. Images are classified according to several criteria: suggestions based on image searches (IMAGE_SEARCH_RETRIEVAL), recently clicked images (RECENT_IMAGE_CLICKS), or suggestions related to the selected theme (VERTICAL_AFFINITY_EXPLICIT_INTEREST, PETACAT_TOKEN_RETRIEVAL).
When no KG entity is present (stand‑alone image), the image feed can use only the docid or visual similarity (label MEAN_EMBEDDING). When available, Google even retrieves the query associated with the image, such as “Freckle makeup natural look” for WW_QUERIES.
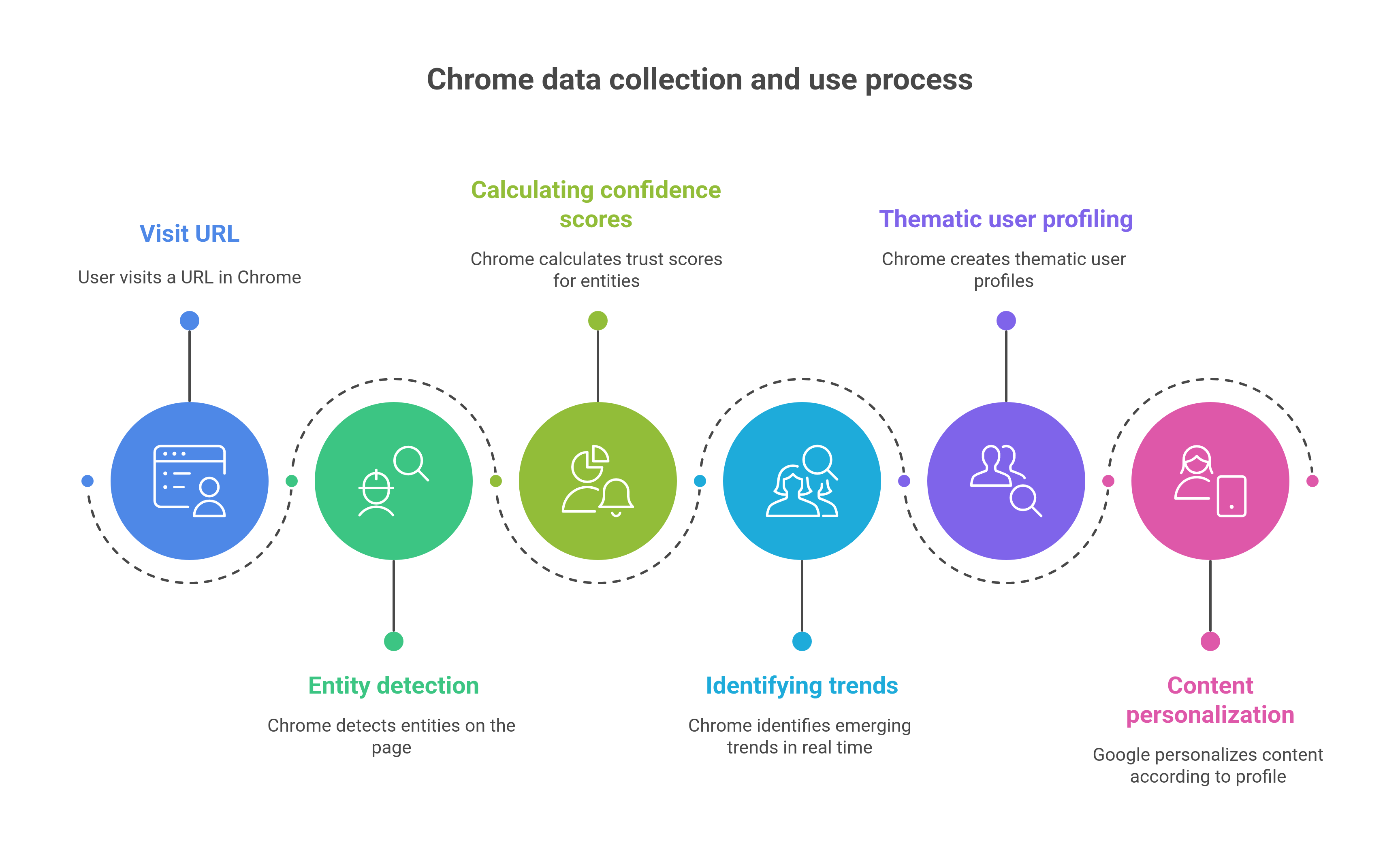
Chrome: the spy that enriches the graph
Contrary to simplistic theories about using Chrome data for ranking, the reality is subtler. Chrome does not directly influence ranking but instead feeds the Knowledge Graph by:
- Detecting the entities visited via each URL
- Calculating confidence scores for every entity
- Identifying emerging trends in real time
- Enabling thematic profiling of users
Each visit therefore deepens Google’s overall understanding of the relationships between entities and users.
The mutations of SEO in the Knowledge Graph era
From keyword optimisation to entity strategy
The revelations about the Knowledge Graph demand a radical shift in SEO thinking. It is no longer about optimising for keywords but about:
- Becoming an entity : being identified and validated in the Knowledge Graph
- Building relationships : anchoring yourself in a network of relevant entities
- Multiplying sources : appearing in varied contexts for triangulation
- Maintaining coherence : aligning every signal around your entity identity
Embeddings in the service of topicality
The discovery of site2vecEmbedding confirms that Google vectorises not only words and documents but entire sites. The siteFocusScore and siteRadius measure overall thematic coherence, penalising sites that scatter their content.
This approach explains recent updates that have hit generalist websites : Google now favours highly specialised sources, deeply anchored within their thematic graph.
Implications for the future: the Knowledge Graph in the service of AI
Gemini and AI Overviews: the KG as factual bedrock
While conventional LLMs regularly hallucinate, Google possesses with its Knowledge Graph a validated, structured factual base. The new systems such as AI Mode do not generate answers ex nihilo but assemble facts drawn from the graph, alongside classic information retrieval, guaranteeing superior reliability.
Ongoing experiments (EntityTriggeringScorerGws, VerticalFactoryCruisesEntities) suggest an even deeper integration, where every query is first resolved in terms of entities before the engine even looks for documents.
Toward a web of interconnected entities
The Knowledge Graph is not a simple enrichment of the SERPs - it forms the web's primary reading grid. In this new reality, visibility will depend less on the content produced than on the ability to slot into this knowledge graph.
For SEO professionals, this means fundamentally rethinking their strategies. The challenge is no longer merely to appear in a list of results, but to exist as a validated entity, continually linked and enriched within Google's Knowledge Graph.
Read more...
- See infographic about Google Knowledge Graph Mining Pipeline
- Replay (in French) of the conference delivered in Marseille, March 2025 by Damien Andell and Sylvain Deauré of 1492.vision: https://www.youtube.com/watch?v=xoQIlYgzOD8.
The talk offered an in‑depth analysis of the pivotal role played by entities and the Knowledge Graph across Google’s entire ecosystem. - Related post on Abondance (in French) : https://www.abondance.com/20250613-1227854-knowledge-graph-le-moteur-cache-derriere-lia-de-google.html
All information presented here comes solely from publicly accessible sources that required no access bypass or intrusion. It is published for informational purposes only.
Want to comment on this post? head over to The Linked In announcement
Authors
Posted on 2025-07-22