Entities everywhere : le Knowledge Graph, architecture invisible de l’empire Google
Le Knowledge Graph n'est plus seulement une base de données enrichissant les résultats de recherche : il est devenu l'infrastructure fondamentale sur laquelle repose toute la stratégie IA et Search du géant de Mountain View.
Un système tentaculaire aux ramifications insoupçonnées
Nos investigations révèlent une architecture d'une complexité vertigineuse. Là où nous pensions voir une simple base de connaissances alimentant les Knowledge Panels, nous découvrons un écosystème interconnecté qui innerve littéralement tous les services Google : Search, Discover, YouTube, Maps, Assistant, et désormais les nouveaux systèmes IA comme Gemini et AI Overviews.
L'obsession de la validation : auteurs et sources de confiance
Google ne plaisante pas avec la fiabilité de ses données. Le système Livegraph, cœur battant du Knowledge Graph, applique un poids de confiance sur chaque triple identifié afin de décider de l’inclure ou non dans le KG. La prise de décision va varier selon la confiance que Google a dans le site ou l’auteur. Par exemple, si l’auteur a un profil déjà validé par Google avec un Knowledge Panel son score sera automatiquement rehaussé. Cette obsession de la vérification se manifeste dans la hiérarchie complexe des namespaces :
- kc: pour les données issues de corpus hautement validés (âge officiel, données gouvernementales)
- ss: pour les webfacts extraits du web (moins fiables mais plus riches), on trouve également quelques ok: pour les shortfacts
- hw: pour les données curées manuellement par des humains
Cette classification n'est pas anodine : elle détermine directement le niveau de confiance accordé à chaque information et son utilisation dans les différents services.
Les entités fantômes : quand Google comble les vides
Une découverte fascinante concerne les "entités non ancrées". Contrairement aux entités officielles possédant un identifiant stable (MID Freebase...), ces entités fantômes flottent dans une zone tampon, utilisées temporairement par les systèmes Google sans être formellement intégrées au Knowledge Graph.
Cette flexibilité permet à Google de réagir en temps quasi-réel aux événements émergents, un avantage stratégique majeur face par exemple aux LLMs traditionnels qui dépendent de données d'entraînement figées.
Le pipeline d'extraction : une machine de guerre sémantique
SAFT, WebRef et la course aux entités
Les systèmes d'extraction de Google fonctionnent 24h/24 pour identifier, classifier et relier les entités. SAFT (Structured Annotation Framework and Toolkit) ne se contente pas d'extraire des noms : il analyse les relations, le contexte, la coréférence, construisant une représentation sémantique complète de chaque document. De nombreux mécanismes sont à l’oeuvre. Quelques exemples :
- SAFT identifie les entités et leurs relations
- WebRef/QRef résout les ambiguïtés (Apple Inc. vs pomme)
- Tractzor et Chain Mining extraient les entités "longue traîne"
- Le score de "singleTopicness" évalue la pertinence...
Les prédicats : l'ADN des relations
Nos analyses révèlent des centaines de prédicats structurant les relations entre entités. Du simple kc:/people/person:age aux relations complexes comme hw:/collection/olympic_athletes:gold medal, chaque prédicat encode une facette spécifique de la connaissance humaine.
Plus intriguant encore, l'apparition de prédicats français (ss:/webfacts:lieu_de_creation_en_franc, ss:/webfacts:mair_mandat) suggère une adaptation locale du Knowledge Graph, potentiellement pour améliorer la pertinence régionale des résultats.
L'impact sur Discover et au-delà
Quand les entités pilotent l'actualité
Les expérimentations récentes de Google (EntityCardDynamicChipsAndSubtitlesLaunch, DeepscamImplicitEntityLaunch) montrent une volonté d'intégrer toujours plus profondément les entités dans l'expérience utilisateur. Sur Discover notamment, chaque carte est désormais associée à un ensemble d'entités qui déterminent sa distribution et sa visibilité.
L'analyse de Damien Andell révèle des mécanismes de mise à jour en temps réel stupéfiants : lors d'émissions comme "Danse avec les Stars", les entités des participants voient leur score de tendance exploser minute par minute, influençant instantanément leur visibilité sur Discover.
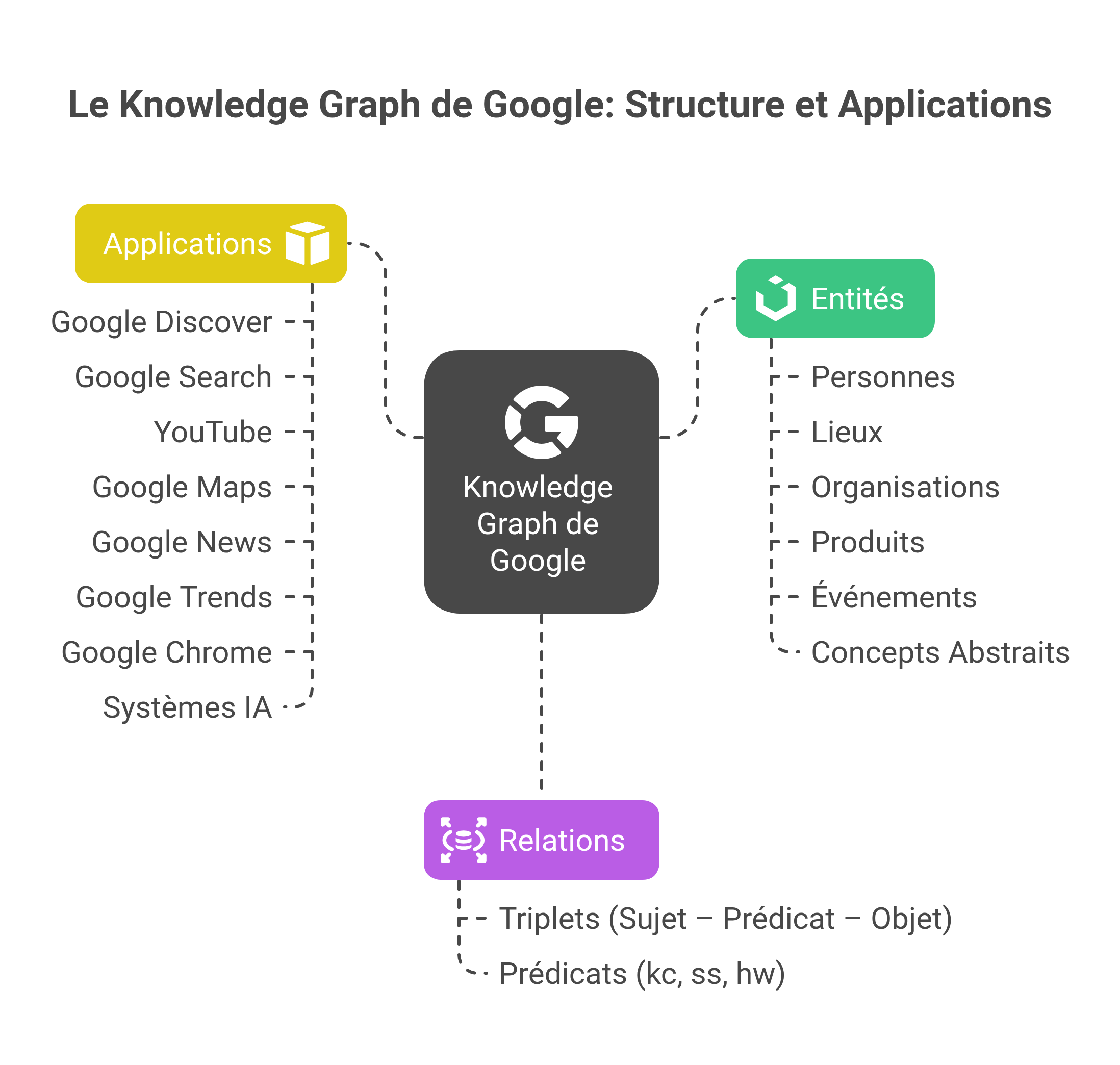
L'Image Feed : quand vos favoris pilotent vos recommandations
Une autre découverte de Damien révèle comment fonctionne le flux d'images (Ember) dans l'application Google, qui coexiste avec Google Discover. Dans l'onglet "Activité", Google stocke les collections d'éléments sauvegardés comme la Watchlist (films/séries) et FavoritePlaces (cartes), en conservant les MIDs des entités correspondantes via l'ActivityHub.
Exemples de stockage d'entités :
"item_type: PLACE", "/m/0c9888""item_type: TVM_ENTITY", "/g/11k9fvbhqw"
Le système devient particulièrement sophistiqué dans le flux d'images. Google croise les topics publicitaires (comme #910 Soups & Stews) avec les MIDs des entités, et le score est boosté par VERTICAL_AFFINITY_EXPLICIT_INTEREST. Les images sont classifiées selon plusieurs critères : suggestions basées sur les recherches d'images (IMAGE_SEARCH_RETRIEVAL), images récemment cliquées (RECENT_IMAGE_CLICKS), ou suggestions basées sur le thème choisi (VERTICAL_AFFINITY_EXPLICIT_INTEREST, PETACAT_TOKEN_RETRIEVAL).
Sans entité KG (image isolée), le flux d'images ne peut utiliser que le docid ou la similarité visuelle (label MEAN_EMBEDDING). Quand disponible, Google récupère même la requête associée à l'image, comme "Freckle makeup natural look" pour WW_QUERIES.
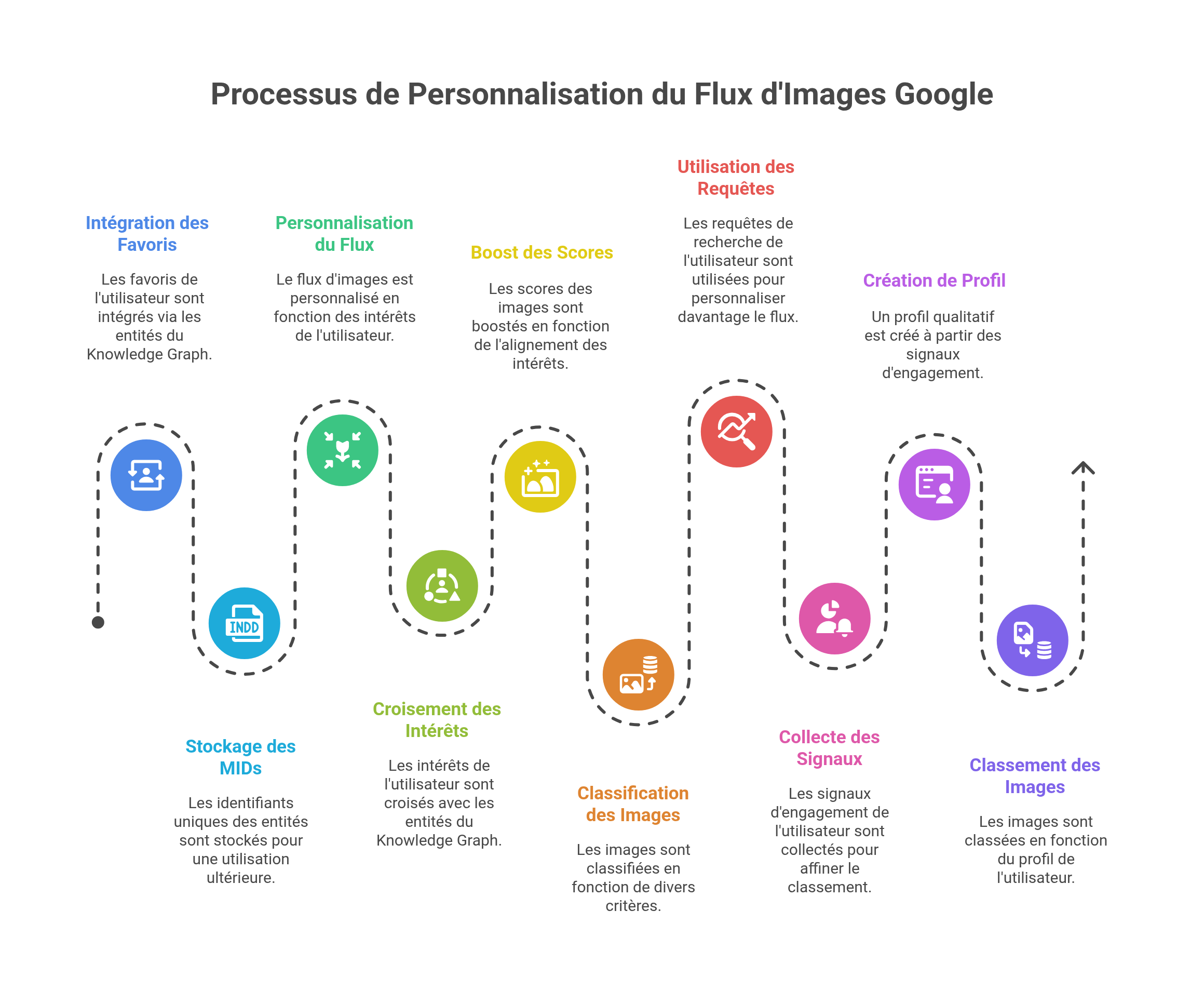
Chrome : l'espion qui enrichit le graphe
Contrairement aux théories simplistes sur l'utilisation des données Chrome pour le ranking, la réalité est plus subtile. Chrome ne sert pas directement au classement mais alimente par exemple le Knowledge Graph en :
- Détectant les entités visitées par URL
- Calculant des scores de confiance par entité
- Identifiant les tendances émergentes en temps réel
- Permettant le profilage thématique des utilisateurs
Chaque visite enrichit ainsi la compréhension globale que Google a des relations entre entités et utilisateurs.
Les mutations du SEO à l'ère du Knowledge Graph
De l'optimisation de mots-clés à la stratégie d'entité
Les révélations sur le Knowledge Graph imposent un changement radical de paradigme SEO. Il ne s'agit plus d'optimiser pour des mots-clés mais de :
- Devenir une entité : être identifié et validé dans le Knowledge Graph
- Construire des relations : s'ancrer dans un réseau d'entités pertinentes
- Multiplier les sources : apparaître dans des contextes variés pour la triangulation
- Maintenir la cohérence : aligner tous les signaux autour de son identité d'entité
L'embedding au service de la topicalité
La découverte du site2vecEmbedding confirme que Google vectorise non seulement les mots et les documents, mais des sites entiers. Le siteFocusScore et le siteRadius mesurent la cohérence thématique globale, pénalisant les sites qui s'éparpillent. (1)
Cette approche explique les récentes mises à jour affectant les sites généralistes : Google privilégie désormais les sources hautement spécialisées, ancrées profondément dans leur graphe thématique.
Implications pour l'avenir : le Knowledge Graph au service de l’IA
Gemini et AI Overviews : le KG comme socle factuel
Alors que les LLMs classiques hallucinent régulièrement, Google dispose avec son Knowledge Graph d'une base factuelle validée et structurée. Les nouveaux systèmes comme AI Mode ne génèrent pas des réponses ex nihilo mais assemblent des faits issus du graphe, en plus de la recherche d’information classique, garantissant une fiabilité supérieure.
Les expérimentations en cours (EntityTriggeringScorerGws, VerticalFactoryCruisesEntities) suggèrent une intégration encore plus poussée, où chaque requête est d'abord résolue en termes d'entités avant même de chercher des documents.
Vers un web d'entités interconnectées
Le Knowledge Graph n'est pas un simple enrichissement des SERPs : il constitue la grille de lecture principale du web. Dans cette nouvelle réalité, la visibilité dépendra moins du contenu produit que de la capacité à s'inscrire dans ce graphe de connaissances.
Pour les professionnels du SEO, cela signifie repenser fondamentalement leurs stratégies. L'enjeu n'est plus seulement d'apparaître dans une liste de résultats, mais d'exister en tant qu'entité validée, reliée et enrichie en continu dans le Knowledge Graph de Google.
Pour en savoir plus
- Lire l’article Abondance associé : https://www.abondance.com/20250613-1227854-knowledge-graph-le-moteur-cache-derriere-lia-de-google.html
- Voir l’infographie sur la pipeline d'Extraction Google Knowledge Graph
- Replay de notre conférence de Marseille, en Mars 2025 "Entities everywhere": https://www.youtube.com/watch?v=xoQIlYgzOD8, où nous abordions le rôle central des entités nommées et du knowledge graph, non seulement pour Google Discover mais également pour l'ensemble de son éco-système.
(1) Lors des masterclass du SEO Summit fin 2024, Sylvain Deauré a présenté ces métriques siteRadius et siteFocus ainsi qu'une méthodologie pour les calculer. Il y reviendra lors d'un Atelier consacré aux usages avancés des embeddings lors du TekNSeo à Toulouse, en Septembre 2025.
Les informations présentées proviennent exclusivement de sources publiques accessibles sans contournement d’accès ni intrusion. Elles sont publiées à titre informatif.
Pour commenter cet article, rendez-vous sur la page de l'annonce linked in
Authors
Posted on 2025-07-22